A journal of IEEE and CAA , publishes
high-quality papers in English on original
theoretical/experimental research
and development in all areas of automation
 Volume 13
Issue 5
Volume 13
Issue 5
IEEE/CAA Journal of Automatica Sinica
| Citation: | M. Gong, H. Zhang, B. Hui, and J. Ma, “TransFM: Visible-to-infrared image translation via flow matching,” IEEE/CAA J. Autom. Sinica, vol. 13, no. 5, pp. 1239–1241, May 2026. doi: 10.1109/JAS.2025.125930

|

| [1] |
J. Liu, X. Li, Z. Wang, Z. Jiang, W. Zhong, W. Fan, and B. Xu, “PromptFusion: Harmonized semantic prompt learning for infrared and visible image fusion,” IEEE/CAA J. Autom. Sinica, vol. 12, no. 3, pp. 502–515, 2025. doi: 10.1109/JAS.2024.124878
|
| [2] |
Y. Ma, X. Wang, W. Gao, Y. Du, J. Huang, and F. Fan, “Progressive fusion network based on infrared light field equipment for infrared image enhancement,”IEEE/CAA J. Autom. Sinica, vol. 9, no. 9, pp. 1687–1690, 2022. doi: 10.1109/JAS.2022.105812
|
| [3] |
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10684–10695.
|
| [4] |
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” in Proc. International Conference on Machine Learning (ICML), 2021, pp. 8748–8763.
|
| [5] |
V. V. Kniaz, V. A. Knyaz, J. Hladuvka, W. G. Kropatsch, and V. Mizginov, “ThermalGAN: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset,” in Proc. European Conference on Computer Vision (ECCV) Workshops, 2019, pp. 606–624.
|
| [6] |
D.-G. Lee, M.-H. Jeon, Y. Cho, and A. Kim, “Edge-guided multi-domain RGB-to-TIR image translation for training vision tasks with challenging labels,” in Proc. IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 8291–8298.
|
| [7] |
B. Hu, C. Gao, S. Liu, J. Guo, F. Chen, F. Liu, and J. Han, “CM-Diff: A single generative network for bidirectional cross-modality translation diffusion model between infrared and visible images,” arXiv preprint arXiv: 2503.09514, 2025.
|
| [8] |
J. N. Paranjape, C. de Melo, and V. M. Patel, “F-ViTA: Foundation model guided visible to thermal translation,” arXiv preprint arXiv: 2504.02801, 2025.
|
| [9] |
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” in Proc. 11th International Conference on Learning Representations (ICLR), 2023.
|
| [10] |
M. Gui, J. Schusterbauer, U. Prestel, P. Ma, D. Kotovenko, O. Grebenkova, S. A. Baumann, V. T. Hu, and B. Ommer, “DepthFM: Fast generative monocular depth estimation with flow matching,” in Proc. AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 3203–3211.
|
| [11] |
J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in Proc. International Conference on Machine Learning (ICML), 2022, pp. 12888–12900.
|
| [12] |
M. A. Özkanoğlu and S. Ozer, “InfraGAN: A GAN architecture to transfer visible images to infrared domain,” Pattern Recognition Letters, vol. 155, pp. 69–76, 2022. doi: 10.1016/j.patrec.2022.01.026
|
| [13] |
Z. Han, S. Zhang, Y. Su, X. Chen, and S. Mei, “DR-AVIT: Toward diverse and realistic aerial visible-to-infrared image translation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, Art. no. 5004213, 2024.
|
| [14] |
G. Parmar, T. Park, S. Narasimhan, and J.-Y. Zhu, “One-step image translation with text-to-image models,” arXiv preprint arXiv: 2403.12036, 2024.
|
| [15] |
F. Mao, J. Mei, S. Lu, F. Liu, L. Chen, F. Zhao, and Y. Hu, “PID: Physics-informed diffusion model for infrared image generation,” Pattern Recognition, vol. 169, Art. no. 111816, 2026. doi: 10.1016/j.patcog.2025.111816
|
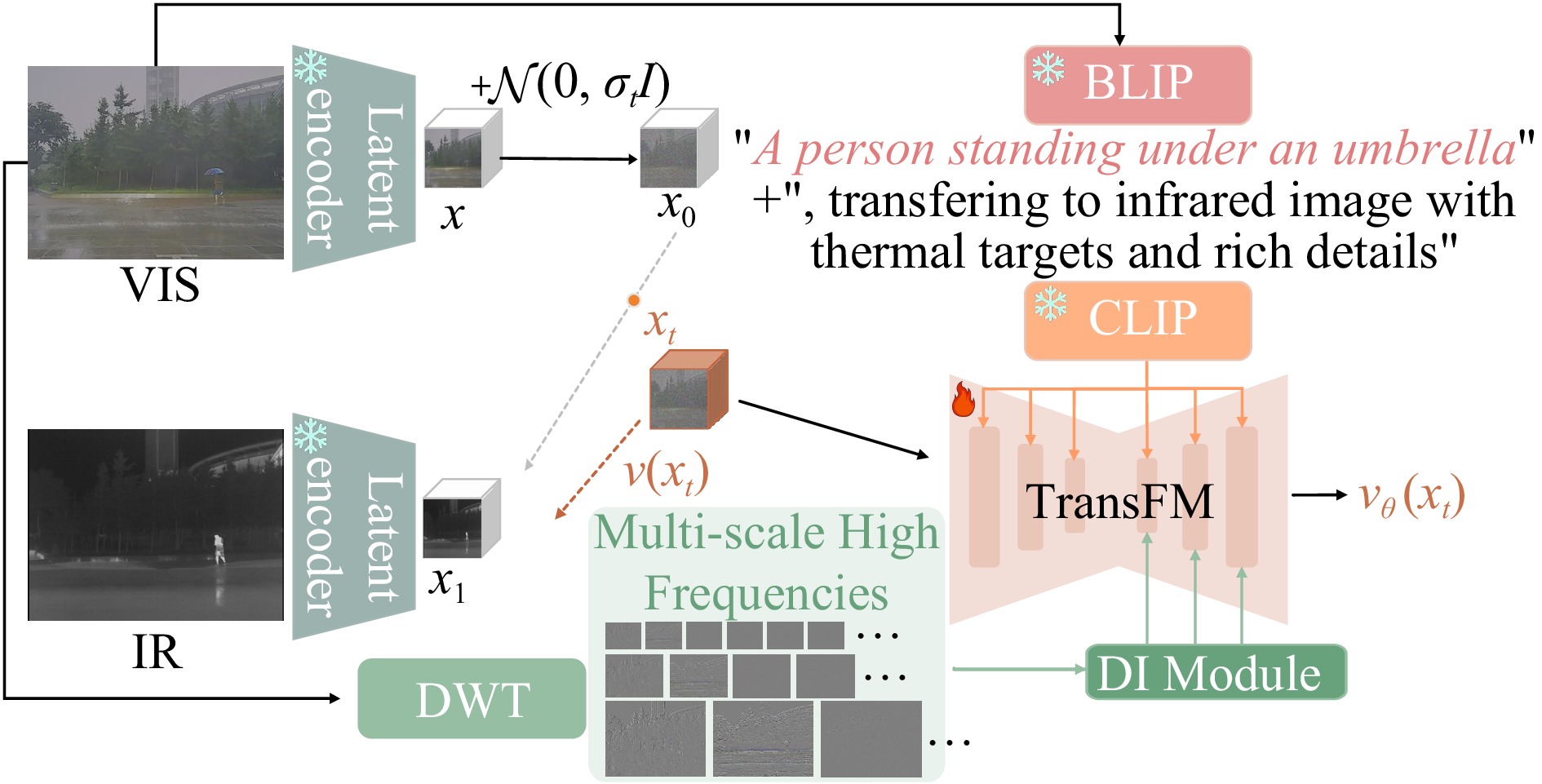
Figures(5) / Tables(4)







 DownLoad:
DownLoad:



